White’s coin puzzle for imprecise probabilities
[Caveat lector: I use a whole bunch of different labels for people who prefer sharp credences versus people who prefer imprecise credences. I hope the context makes it obvious which group I’m referring to in each instance. Also, this was all written rather quickly as a way for me to get my ideas straight. So I might well have overlooked something that defuses the problems I discuss. Please do tell me if this is the case.]
On two occasions now people have told me that there’s this paper by Roger White that gives a pretty strong argument against having imprecise degrees of belief. Now, I like imprecise credence, so I felt I needed to read and refute this paper. So I sat out on my tiny balcony in a rare spell of London sunshine and I read the paper. I feel slightly uneasy about it for two different reasons. Reasons that seem to pull in different directions. First, I do think the argument is pretty good, but I don’t like the conclusion. So that’s one reason to be uneasy. The other reason is that it feels like this argument can be turned against sharp probabilists as well…
The puzzle goes like this. You don’t know whether or not the proposition “P” is true or false. Indeed, you don’t even know what proposition “P” is, but you know that either P is true or ¬P is true. I write whichever of those propositions is true on the “Heads” side of a coin, after having painted over the coin such that you can’t tell which side is heads. I write the false proposition on the tails side. I am going to flip the coin, and show you whichever side lands upwards. You know the coin is fair. Now we want to know what sort of degrees of belief it is reasonable to have in various propositions.
It seems clear that your degree of belief in the proposition “The coin will land heads” should be a half. I’m not in the business of arguing why this is so. If you disagree with that, I take that to be a reductio of your view of probability. Whatever else your degrees of belief ought to do, they ought (ceteris paribus) to make your credence in a fair coin’s landing heads 1/2.
What ought you believe about P? Well, the set up is such that you have no idea whether P. So your belief regarding P should be maximally non-committal. That is, your representor should be such that C(P)=[0,1], the whole interval. This is, I think, the strength of imprecise probabilities over point probabilities: they do better at representing total ignorance. Your information regarding P and regarding ¬P is identical, symmetric. So, if you wanted sharp probabilities, the Principle of Indifference (PI, sometimes called the Principle of Insufficient Reason) suggests that you ought to consider those propositions equally likely. That is, if you have no more reason to favour one outcome over any other, all the outcomes ought to be considered equally likely. In this case C(P)=1/2=C(¬P). In sharp probabilities, you can’t distinguish total ignorance from strong statistical evidence that the two propositions are equally likely. Consider proposition M: “the 1000th child born in the UK since 2000 is male”. We have strong statistical evidence that supports assigning this proposition equal weight to the proposition F (that that child is female). I’ll come back to that later.
So what’s the problem with imprecise probabilities according to White? Imagine that I flip the coin and the “P” side is facing upward. What degrees of belief ought you have now in the coin’s being heads up? You can’t tell whether the heads or tails face is face up, so it seems like your degree of belief should remain unchanged: 1/2. Given that you can’t see whether it’s heads or tails, you’ve learned nothing that bears on whether P is the true proposition. So it seems that your degree of belief in P should remain the same full unit interval: [0,1].
But: you know that the coin landed heads IF AND ONLY IF P is true. This suggests that your degree of belief in heads should be the same as your belief in P. But they are thoroughly different: 1/2 and [0,1]. So what should you do? Dilate your degree of belief in heads to [0,1]? Squish your degree of belief in P to 1/2? Neither proposal seems particularly appetising. So this is a major problem, right?*
What I want to do now is modify the problem, and try and explore intuitions about what sharp credencers should do in similar situations. First I should note that the original problem is no problem for them, since PI tells them to have C(P)=1/2 anyway, so the credences match up. But I worry about this escape clause for sharp people, since it is still the case that the reasons for their having 1/2 in each case are quite different, and it seems almost an accident or a coincidence that they escape…
Consider a more general game. I have N cards that have a number 1..N on one side of each. The reverse sides are identical. Now, on those reverse sides I write a proposition as before. On card number 1 I write the true proposition out of P and ¬P. On the remaining 2..N I write the false one. Again you don’t know which is which etc. Now I shuffle the cards well, pick one and place it “proposition side up” on the table. For simplicity, let’s say it says “P”. I take it as obvious that your credence in the proposition “This is card number 1” should be 1/N. What credence should you have in P? Well, PI says it should be 1/2. But it should also be 1/N, since we know that P is true IF AND ONLY IF this is card number 1.
Imagine the case where N is large, 1 million, say. I get the feeling that in this case, you would want to say that it is overwhelmingly likely that P is false: 999,999 cards have the false proposition on, so it’s really likely that one of them has been picked. So my credence in P being true should be something like 1/1,000,000. Put it the other way round. Say there’s only 1 card. Then if you see the card says “P”, that as good as tells you that P is true, so your credence should move to 1.
On the other hand, if we’re thinking about a proposition we are very confident in, say A: “Audrey Hepburn was born in Belgium” (it’s true, look it up.). Let’s say C(A)=0.999 (not 1 because of residual uncertainty regarding wikipedia’s accuracy.). Now, if we have 2 cards and the one drawn says A, that’s good reason to believe that that card is the number 1 card. So in this case, it’s the belief regarding the card that moves, not the belief regarding the proposition.
What about the same game but with a million cards? Despite my strong conviction that Audrey Heburn was, if briefly an Ixelloise (?), the chance of the card drawn being number 1 is so small that maybe that should trump my original confidence and cause me to revise down my belief in A.
Here’s another trickier case. Now imagine playing the same game with some proposition I have strong reason to believe should have credence 1/2, like M defined above. And let’s say we’re playing with only 3 cards. For simplicity, let’s imagine that M is shown. How should your credences change in this situation? Again, it seems that C(M)=C(1) is required by the set up of the game. But I’m less sure which credence should move.
In any case, is there a principled way to decide whether it’s your belief about the card or your belief about the proposition that should change. And if there isn’t, doesn’t this tell against the sharp credentist as much as against the imprecise one?
On objection you might have is that this is all going to be cleared up by applying some Bayes’ theorem in these circumstances, since in these cases (as opposed to White’s original one) see which proposition is drawn really does count as learning something. I don’t buy this, since the set up requires that your degrees of belief be identical in the two propositions. Updating on one given the other is going to shift the two closer together, but I don’t think that’s going to solve the problem.
________________
* The third option, a little squish and a little dilate to make them match seems unappealing, and I ignore it for now, since it seems to have BOTH problems that the above approaches do…
World Cup gives insight into financial crisis
It has been reported today that JP Morgan analysts have predicted that England will win the world cup. Their analysis suggests that the schedule favours England over the tournament favourites Brazil and Spain. But there’s a flaw in their reasoning. One of the factors looked included in their model is the odds offered on various teams winning on Betfair.com. Since betfair is an English website, it seems there is a danger of “the market’s” assessment of relative likelihoods of various teams winning being skewed in favour of the home country. My guess is that this analysis’ outcome wouldn’t be robust if you substituted in a different betting exchange’s odds, say from a different country. Imagine taking, say, Italy’s biggest betting exchange and using their odds. I doubt England would prevail there. So either they should pick the odds offered by a betting exchange from a country with no realistic chance of winning (so the team with a chance don’t have their odds skewed), or aggregate the odds of various markets from various countries.
And how does this give an insight into the financial crisis? The mistake made in both cases is the same. It is to assume that the market price reflects the value of the asset. Economists call this the Efficient Market Hypothesis. In the world cup prediction case, the assumption is that odds offered reflect the real chance of the outcome occurring.
Odds offered by proper bookies obviously don’t straightforwardly reflect their expert opinion of the chance of the event: bookies shorten odds in order to make a profit. (Consider roulette: betting on red doubles your money, but the chance of red is slightly less than a half, and therein lies the house advantage; the profit.) Another confounding factor here is that odds on England offered by English bookies are shortened a lot, since many more people will bet on England here than in other countries (regardless of odds), so if England did win bookies would have to pay out a lot. So bookies make the odds shorter to limit their exposure to huge payouts. But betfair isn’t like a normal bookies. It’s a betting exchange. It’s much more like a stock exchange. The thing that is being bought and sold are bets. This should counteract some of the distorting effects inherent in standard bookie’s odds. But there is still a bias in favour of England, I think. People on betfair aren’t all betting as disinterested fully informed rational agents. So there is no reason to think the odds offered on England really do reflect the best estimate of England’s chance of winning. (I mean, come on. Emile Heskey is in the squad. Compared with Spain, who will probably leave Dani Guiza on the bench…)
To be clear: the problem is not with the idea of using the market in general, but the problem is that the betting exchange they used has a clear bias that JP Morgan don’t seem to have acknowledged. (From what I’ve read in the papers. Maybe they did, but I expect not). The insight into the financial crisis is this: if JP Morgan didn’t spot this flaw and they SURVIVED, imagine how dumb the financial companies that folded must have been!
Here’s another take on analysing the world cup which won’t be as popular in the England, since it doesn’t have England winning…
Important caveats: I know very little about economics and even less about football. But this is the internet, so my opinion is just as important as all those so called experts.
Reverse LaTeX?
I know LaTeX better than I know how to do accents in word or equivalent. What I’d find useful is a way to type TeX commands and have something automagically replace that command with the unicode character.
For example: I’d type \’a and it would transformify into á. That would be cool. I can’t imagine many people would use it…
I actually quite like how my phone handles it.* You hold down the letter in question and a little menu appear containing a useful symbol, and then various accents you can put on the letter. Could that be implemented on laptops? Could you hold down the “a” key until a menu of accents popped up? I think that might have more appeal than my TeX geekery idea…
____________
*Yeah. I typed this blog post on my phone. Welcome to the twenty first century, baby!
Graduate Conference on Philosophy of Probability
I am organising this years LSE Philosophy of Probability Graduate Conference. This has been at least one of the reasons I have failed to blog for ages. But fear not! I am pondering some things that could well become blog posts. Here is a list of them:
- More stuff about a logic of majority
- Dutch book arguments (what they actually prove, and under what conditions)
- Pluralism (species concept pluralism, logical pluralism, pluralism about interpretations of probability)
- More fallibilist realism (following on from reading Kyle Stanford’s book and discussions with some LSE chaps)
- A couple more awesome headlines
- Perhaps some stuff about learning emacs, auctex and reftex. (And biblatex, tikz, beamer…)
As and when these posts achieve maturity, I’ll link to them here.
The pessimistic induction and Descartes’ evil demon
The pessimistic induction (PI) says something like this: Previous scientific theories have been wrong, so we shouldn’t believe what current science tells us. But let’s modify that with an “optimistic induction” that there is continuity through theory change (the wave nature of light survived the abandonment of the ether theory…) and our methods are improving. The PI then seems to be saying something like this: It might be the case that this or that particular theoretical entity will be discarded some time in the future. Well, this “might” claim looks a lot like Descartes’ evil demon argument for radical scepticism.
Descartes’ argument says that you might be being tricked by a powerful evil demon. The upshot is supposed to be a radical scepticism about the reality of the things we think we see. So I see a table, but I might be being tricked, so I should not believe the table exists. But obviously this brand of radical scepticism is not the orthodoxy. Why? Because another way to approach the evil demon is a kind of “fallibilism” that holds that I should believe that what I see exists, while accepting that I might be wrong, I might be being tricked by this demon.
In much the same way, I think the right approach to the PI (as moderated by the optimistic comments made above) is to say that the right approach is a “fallibilist realism” which says that while I can be confident that some element of current science will be discarded, on the whole I should believe in theoretical entities.
I think this picture fits nicely with scientific practice as well. Doing science whilst not endorsing the reality of the entities one deals with seems difficult. I mean, if I were a scientist and I didn’t believe in electrons, I’d find it difficult to theorise about them… Or to put it another way, if I were a young creationist, I would not become a paleontologist. (OK, cheap shot. Sorry). The point is that on the whole, scientists will believe in what they study, but will of course accept they might be wrong.
So this point seems obvious enough that I’m surprised I haven’t read about it before. I’m interested in hearing about any precedents of this position in the literature.
Nonprobabilistic Cognitive Decision Theory
I’ve just got back from a philosophy of probability conference in Oxford. It was very interesting.
Here are some thoughts I had about Hilary Greaves’ talk. The project is to flesh out an idea of epistemic rationality by analogy to practical rationality and practical decision theory. The idea is that in the “Cognitive Decision Theory” the sort of acts you are interested in are various beliefs you could adopt. Or various belief functions you could adopt. There is an idea of cognitive utility which is supposed to be a measure of how epistemically good you think a certain belief state is. Greaves and Wallace 2006 show that it is rational to update by conditionalisation when some conditions are satisfied.
The thing is, their theory starts by assuming that belief is represented by a probability function. This is a fairly standard, but perhaps too restrictive assumption. To paraphrase from Greaves’ talk yesterday: there are various intuitions we have about epistemic rationality. If we can derive lots of these from the theory, without building them in to the theory, then that’s a good thing. The less we have to start with and still get back all (or most) of our intuitions, the better.
So let’s apply that to the issue of presupposing that belief is probabilistically coherent. Why not start with some more general belief function set up and see under what circumstances probability measures are the uniquely rational way to structure your beliefs? The answer to this question is, I imagine, “because it’s really hard to prove anything about any more general framework”. True enough. But what about the case where belief is represented by a set of probability measures? How much of the argument of Greaves and Wallace goes through in the case where you just replace every instance of “probability measure, 
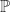
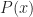
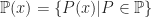
A large spread of probability measures in an agent’s representor can be seen as indicating that agent’s desire to withhold judgment pending more conclusive evidence. I think that’s a valuable thing to want to model formally. The probability measure representation of belief requires that the agent has to be maximally probabilistically opinionated, which I don’t think is epistemically rational…
Presumably in this broader context it is no longer possible to prove that conditionalise is the best updating rule, but perhaps some analogue of conditionalise which incorporates a method for conditionalising on sets of probability measures still works.
Here’s a suggestion as to when it would be rational to have probabilistic credences. If your epistemic utility function were close to the scoring rules of Joyce 1998 then perhaps probabilism would be uniquely rational.
In general however, I think that as well as accuracy (which moves you towards probabilism), there is another source of epistemic utility. Or rather, a source of epistemic disutility which you want to avoid. Accuracy means you derive utility from being close to the truth. You derive disutility from being far from the truth.
Here’s a kind of geometrical analogy to illustrate the sources of utility in contention. Alice’s credence in an event is represented by some subinterval ![A \subseteq [0,1]](https://s0.wp.com/latex.php?latex=A+%5Csubseteq+%5B0%2C1%5D+&bg=ffffff&fg=1c1c1c&s=0&c=20201002)


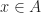
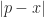
Backwards compatibility
A long time ago, I decided to see if I could rewrite an essay I’d written as an undergrad in Open Office in LaTeX. I gave up soon after because (1) it was pointless since I had since then written a better paper (in LaTeX) on the same subject (the conventionality of spacetime geometry, if you must know) and (2) it was really irritating going through doing things like changing “…” into “…” and so on.
Now, recently I was again recovering old ground and I wanted to write something similar to something I mentioned in an essay I wrote (in LaTeX) as an MA student (About coin flipping and partitioning the space of initial conditions…). I was surprised to discover that even that was laborious to update. I had to do things like go through and replace \citet and \citep with \textcite and \parencite as appropriate. This is because I moved to using biblatex rather than bibtex. I know about the natbib=true compatibility option, but it doesn’t behave properly all the time, particularly with multiple citations… And I had to add signposts to my \labels. That is, write \label{fig:zebra} rather than \label{zebra}. OK, “had to” is probably a bit strong. I wanted to, because I think it’s a good idea to signpost whether it’s a figure or an equation or a section or what have you that you’re referring to.
Today I discovered that it is reccommended that I use \(…\) instead of $…$ for inline maths in LaTeX. This means that even a paper I wrote a couple of months ago (about the principle of indifference) which I now want to work on again has to be updated in a non trivial way before I can use it. (This is a change I can’t just do Find and Replace for… On the other hand, it’s an aesthetic thing rather than a functionality thing. $…$ still works fine, but I like to follow proper practice…)
So I suppose that means I should stick to writing about new stuff rather than recovering old ground if I want to avoid having to laboriously fix minor pseudoproblems with my LaTeX code…
